ExaStor is high-performance scale-out storage optimized for AI/ML workloads. The Luster-based parallel distributed file system is suitable for high-density, large-scale storage workloads that require extreme I/O and scalability, such as AI/ML and big data analysis.
Storage can easily become a main cause of bottleneck when it is not prepared for fast growing AI/ML workloads
Escalating storage costs
AI/ML workflow requires tremendous amount of storage space and network traffic which leads to more operational costs
Increasing operational overhead
To fully support the dynamic needs of AI applications, storage must provide transparent monitoring and insights throughout the pipeline
Exascale storage for high-performance workloads
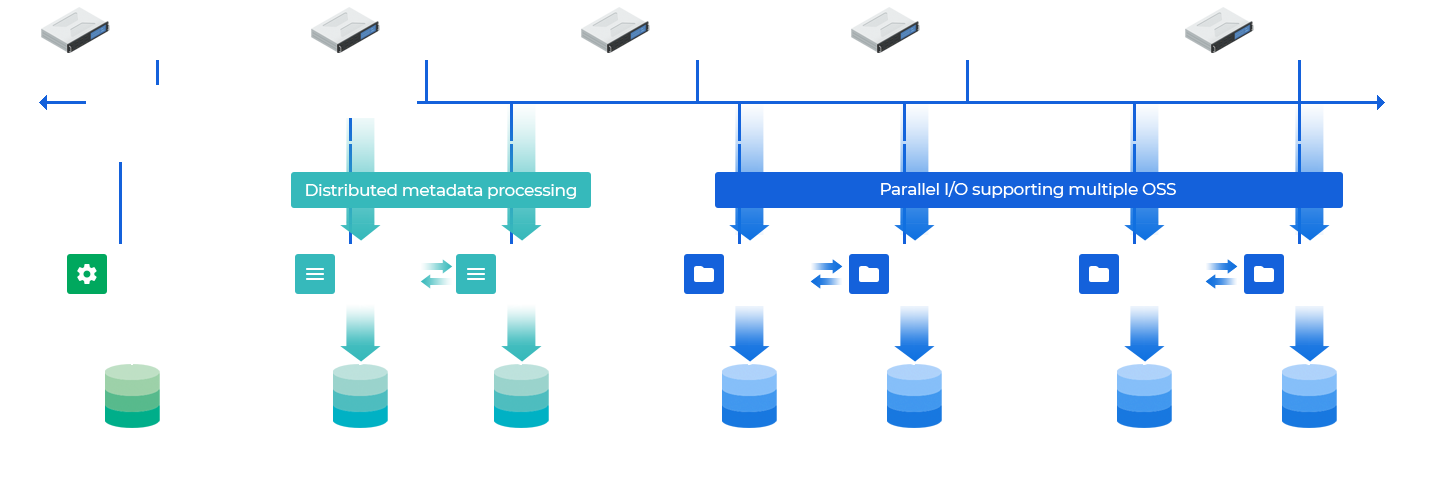
High-performance Parallel File System
Provide high-speed parallel I/O to every data in the storage cluster
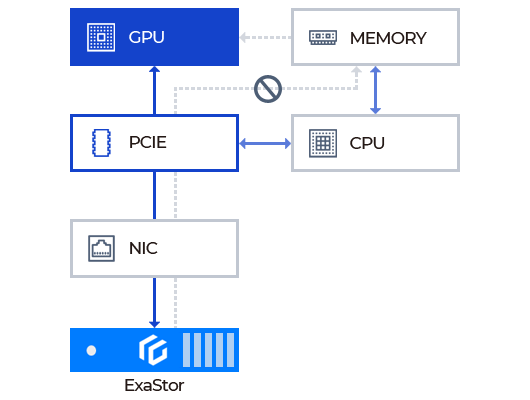
NVIDIA® GPUDirect® Storage Support
Support NVIDIA GPUDirect Storage for direct memory access between GPU and storage
Storage Type in All Scenarios
Leverage NVMe all-flash, SSD and HDD hybrid configuration
Flexible Deployment and Scalability
Choose how to deploy or scale your storage that suits your environment
Up to 40GB/s per Node
Delivers 40GB/s sequential read throughput with all-NVMe storage system
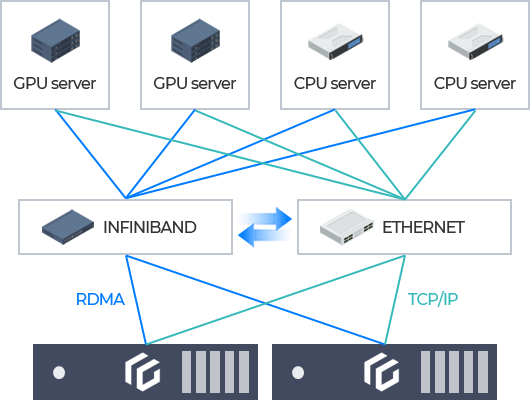
RDMA-powered File Service
Supports NFS over RDMA protocol with InfiniBand EDR and HDR network
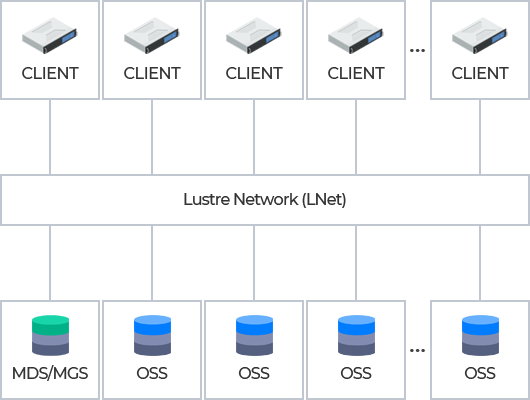
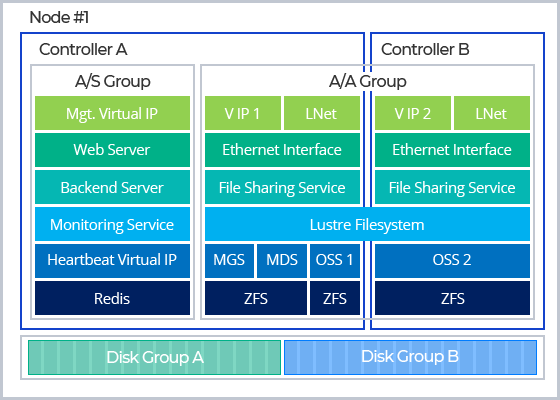
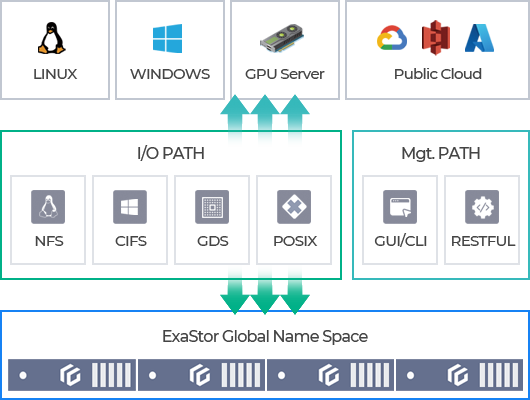
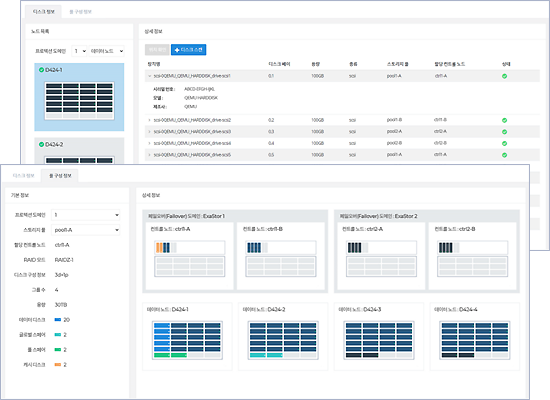
System Architecture
High-performance distributed file storage optimized for AI/ML workloads
High-performance
High Availability
Scalability and Efficiency
Streamlined Management
High-performance Parallel File System
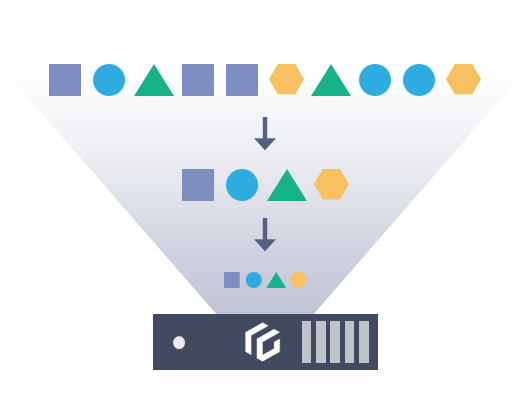
Allows parallel data access through Luster parallel file system, with high-speed file sharing and petabyte-level scalability through its parallel I/O architecture. Files are distributed and stored in objects across the cluster through global namespace.
NVIDIA® GPUDirect® Storage Support
Provides a storage interface to accelerate GPU applications, minimizing CPU and memory load. Maximizes GPU performance by providing a distributed file system IO driver module for applications running on GPGPU.
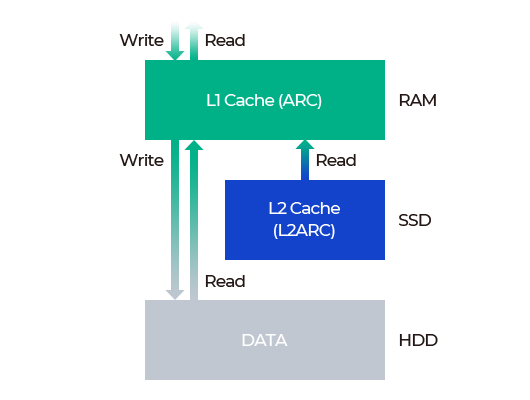
Flash-based Level 2 Cache
Can leverage SSD drives as secondary read cache, extending the main memory cache. When the main memory is full, the system can perform read request on the allocated cache drive, instead of using slower hard drives.
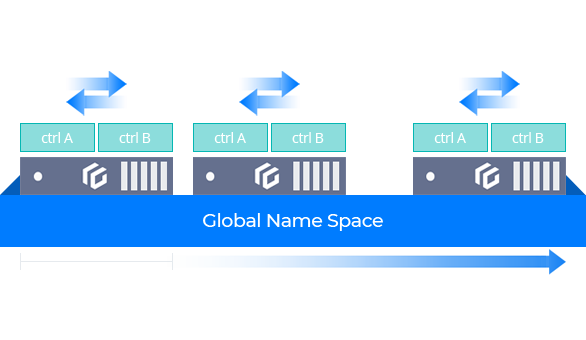
Hardware Redundancy
Redundancy based on dual controllers ensures service continuity through automatic failover in the event of a controller failure. This architecture effectively eliminates the risk of split-brain scenarios during data synchronization, ensuring data integrity and reliability. (※ dual controller model only)
High Availability Architecture
Ensure uninterrupted services by active-active storage redundancy architecture.
Minimize interconnectivity between resources as well as the complexity of active-active configuration to provide instant recovery through partial failover.
Multi-Rail Network
Supports parallel network I/O with multi-rail configuration utilizing both TCP/IP and RDMA network. Network traffics are automatically distributed through load balancing to prevent bottleneck while optimizing the overall network performance.
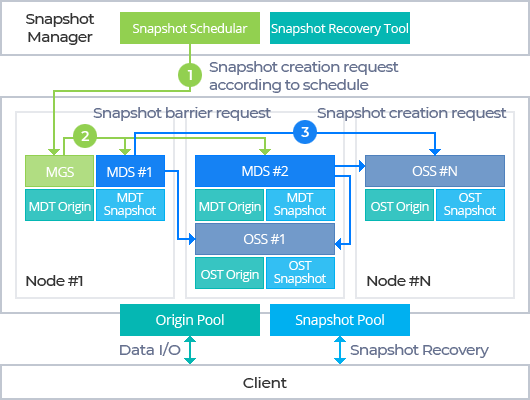
Flexa Snapshot Manager
Leverage the power of the Global Write Barrier of Flexa Snapshot Manager to take instant snapshots across all storage clusters without any system downtime. Snapshots are swiftly generated through copy-on-write by capturing only the changes, operating deep within the file system layer to ensure minimal impact on metadata performance.
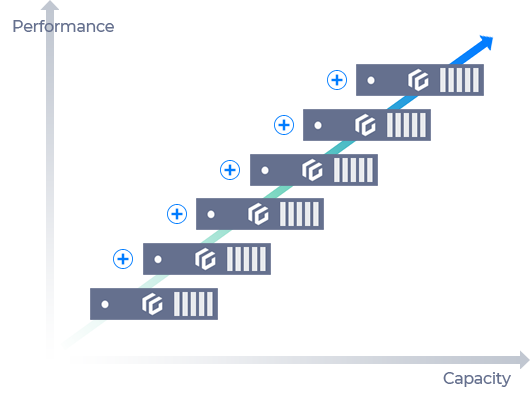
Scale-out Architecture
Effortlessly scale your storage capacity by dynamically adding nodes online. You can achieve massive storage space in petabyte-level in a single system, while having linear performance boosts through parallel scaling. This approach not only minimizes the scale of initial adoption but also ensures cost-effective storage management tailored to your business needs and data growth.
Dynamic Storage Scaling
Optimize your high-capacity, high-density storage with a cutting-edge storage enclosure that supports up to 108 SAS drives in a compact 4U form factor. When scaling up with the E484 model, you can install up to 408 disks, configuring a massive 8.16PB of physical capacity. This scalable architecture ensures your storage infrastructure can grow seamlessly with your data demands.
Flexible Volume Management
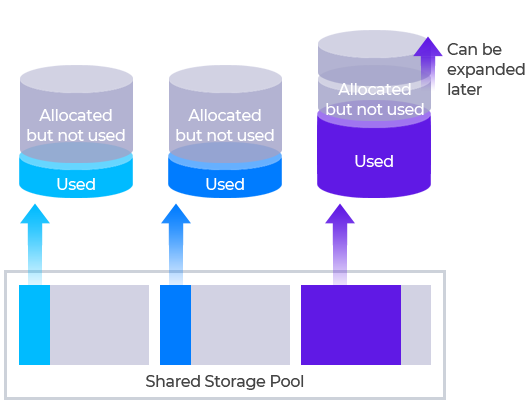
Enhance your storage efficiency with thin provisioning, to allocate logical space beyond the current physical capacity by anticipating future growth trends. This maximizes capacity utilization while providing flexible and elastic capacity management, ensuring your storage resources adapt seamlessly to evolving demands.
Storage Space Optimization
Achieve optimal storage efficiency with real-time data compression, which reduces I/O bandwidth and maximizes storage space utilization. This advanced technology also delivers integrity checks on compressed data, ensuring the detection of data corruption and maintaining data integrity.
Multi-Protocol Support
ExaStor supports a wide range of protocols, including NFS, CIFS, GPUDirect Storage, POSIX-compliant interfaces, and RESTful APIs, ensuring that heterogeneous users and applications can seamlessly access its global namespace.
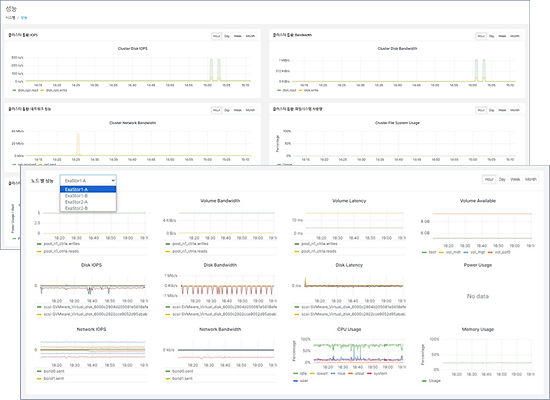
Advanced Performance Monitoring
With our dedicated management software, you can effortlessly track the IOPS and bandwidth for clusters and local volumes. It provides real-time monitoring of network I/O performance for every controller, file system usage, power consumption, and CPU/memory utilization per controller, ensuring visibility of your system’s performance metrics.
Comprehensive System Monitoring
Monitor system usage and availability across clusters and local volumes, including NFS, CIFS, and file system clients. Our dedicated management software enables real-time tracking of disk health and location within the system, ensuring efficient and effective management.
Integrated Lineup
Integrated Dual-controller Architecture
Features dual-controller hardware architecture with integrated management and data nodes
Supports high availability with an active-active setup within a single chassis
Up to 40GB/s performance per node with NVMe SSDs
Start with a single node with the ability to scale in single-node increments
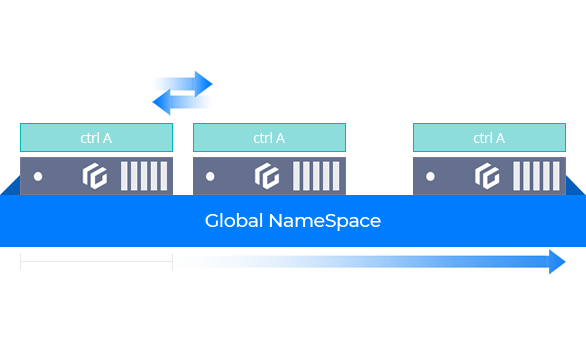
Integrated Single-controller Architecture
Features an integrated management/data node design based on single-controller hardware
Supports high-availability with mirrored nodes
Can be configured as all-NVMe or SAS hybrid
Requires minimum of 1 node, scalable in 1-node increments
Separated Lineup
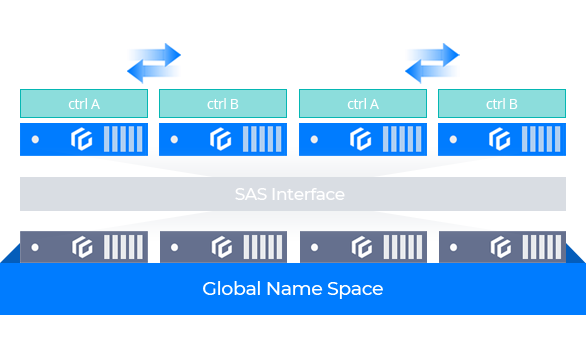
Separated Single-controller Architecture
Features a single controller hardware architecture with management node and data node separated
Utilizes SAS/SATA interface for logical disk sharing
Supports a 2-node high availability setup and a 4-node 3+1 RAID configuration
Begins with a 4-node set and can be expanded per set
Are you interested in our products? Get in touch with Gluesys.